426 просмотров
Оглавление
Смерть от тысячи микросервисов
https://renegadeotter.com/2023/09/10/death-by-a-thousand-microservices.htmlИндустрия программного обеспечения еще раз осознает, что сложность убивает.
Церковь сложности
Есть довольно известный скетч, в котором инженер объясняет руководителю проекта, как работает слишком сложный лабиринт микросервисов, чтобы узнать день рождения пользователя — и все равно не может этого сделать. Сцена точно описывает абсурдность состояния нынешней технологической культуры. Мы смеемся, но поднимать этот вопрос в серьезном разговоре равносильно профессиональной ереси, делая вас практически непригодным для работы.

Как мы здесь оказались? Как наша цель заключалась не в решении поставленной задачи, а в поджоге кучи денег путем решения проблем, которых у нас нет?
Идеальный шторм
В недавней истории есть несколько вещей, которые, возможно, способствовали нынешнему положению. Во-первых, целая армия разработчиков, пишущих JavaScript для браузера, начала идентифицировать себя как «full-stack», погружаясь в серверную разработку и асинхронный код. JavaScript — это JavaScript, верно? Какая разница, что вы создадите с его помощью — пользовательские интерфейсы, серверы, игры или встроенные системы. Верно? Node все еще был своего рода учебным проектом одного человека, а JavaScript тогда был крайне проблематичным выбором для разработки серверов. Указание на это, еще зеленым разработчикам серверной части, обычно приводило к большому раздражению и пыхтению. В конце концов, это все, что они знали. Мира за пределами Node фактически не существовало, путь Node был единственным известным путем, и это послужило источником упрямого, догматического мышления, с которым мы имеем дело по сей день.

А затем постоянный поток ветеранов FAANG начал сливаться с рекой стартапов, обучая новоиспеченных и очень впечатлительных молодых серверных инженеров JavaScript. Апостолы Церкви Сложности настойчиво заявляли, что «то, как они действовали в Google», было неоспоримым и правильным, даже если это не имело смысла в нынешнем контексте и размере. Что значит, что у вас нет отдельной службы пользовательских настроек? Это просто не масштабируется, братан!
Но во всем этом легко обвинить ветеранов и новичков. Что еще происходило? Ах да, легкие деньги.
Что вы делаете, когда у вас полно венчурного капитала? Конечно, вы не гонитесь за прибылью! Я не раз получал электронные письма от руководства, в которых просили всех быть в офисе, наводить порядок на своих столах и выглядеть занятыми, поскольку по офису собирались пройти парадом жилеты Patagonia. Инвесторам нужно было увидеть взрывной рост, но не прибыльность, нет. Им просто нужно было посмотреть, как быстро компания сможет нанять сверхдорогих инженеров-программистов, чтобы сделать… что-нибудь.
И теперь, когда у вас есть эти разработчики, что вы с ними делаете? Они могли бы создать более простую систему, которую легче развивать и поддерживать, или они могли бы создать чудовищное созвездие «микросервисов», которое никто толком не понимает. Микросервисы — новый способ написания масштабируемого программного обеспечения! Собираемся ли мы просто притвориться, что понятия «распределенные системы» никогда не существовало? (Опустим весь разбор нюансов о том, что микросервисы не являются настоящими распределенными системами).
В те времена, когда технологическая индустрия не была таким уж раздутым фарсом, распределенные системы уважали, боялись и вообще избегали, оставляя их только как оружие последней инстанции для особо серьезных проблем. В распределенной системе все становится более сложным и трудоемким — разработка, отладка, развертывание, тестирование, устойчивость. Но я не знаю — может быть, сейчас все супер просто, потому что у нас есть соответствующий инструментарий.
Не существует стандартного инструментария для разработки на основе микросервисов — нет общей среды. В 2020-х годах работа над распределенными системами стала лишь незначительно проще. Dockers и Kuberneteses мира сего не устранили волшебным образом сложность, присущую распределенной установке.
Мне нравится ссылаться на этот отчет о 5-летнем аудите стартапов, поскольку он наполнен здравыми выводами, основанными на веских доказательствах (и платных идеях):
…Проверенные нами стартапы, которые сейчас преуспевают лучше всего, обычно придерживаются почти наглого подхода к проектированию «сохраняйте простоту». Ум ради ума ненавидели. С другой стороны, компании, в которых мы говорили: «Ого, эти люди чертовски умные», по большей части исчезли.
Буквально – «сложность убивает».
Аудит выявил интересную закономерность: многие стартапы испытывали своего рода синдром коллективного самозванца, создавая понятные, простые и производительные системы. Существует догма, запрещающая начинать работу с микросервисами с первого дня, независимо от проблемы. «Все занимаются микросервисами, а у нас есть единый монолит Django, поддерживаемый всего несколькими инженерами, и экземпляр MySQL — что мы делаем не так?». Ответ был почти всегда: «ничего».
Точно так же опытные инженеры часто испытывают колебания и неадекватность в современном мире технологий, и хорошая новость в том, что нет, вероятно, это не вы. Команды часто притворяются, будто занимаются «веб-масштабированием», прячась за библиотеками, ORM и кешем — будучи уверенными в своих знаниях (они разгромили этот Leetcode!), но они могут даже не знать об основах индексации баз данных. Вы действуете в море неоправданной самоуверенности, расточительства и Даннинга-Крюгера, так кто же здесь на самом деле самозванец?
В монолите нет ничего плохого
Идея о том, что невозможно расти без системы, похожей на печально известную диаграмму военной стратегии в Афганистане, во многом является мифом.
Dropbox, Twitter/X, Facebook, Instagram, Shopify, Stack Overflow — эти и другие компании начинали как монолитные базы кода. Многие по сей день имеют в своей основе монолит. Stack Overflow вызывает гордость за то, как мало оборудования им нужно для работы огромного сайта. Shopify по-прежнему остается монолитом Rails, использующим проверенный и надежный Resque для обработки миллиардов задач.
WhatsApp стал сверхновой благодаря монолиту Erlang и 50 инженерам. Как?
WhatsApp сознательно сохраняет небольшой штат инженеров — всего около 50 инженеров.
Отдельные инженерные группы также невелики и состоят из 1–3 инженеров, и каждая группа обладает значительной автономией.
Что касается серверов, WhatsApp предпочитает использовать меньшее количество серверов и вертикально масштабировать каждый сервер в максимально возможной степени.
Instagram был приобретен за миллиарды — с командой из 12 человек.
И вы представляете себе Threads как проект, охватывающий весь Мета-кампус? Неа. Они следовали модели Instagram. Вот их команда:

Возможно, утверждение, что ваша конкретная проблемная область требует чрезвычайно сложной распределенной системы и открытого офиса, доверху набитого турбо-гениями, просто переходит в высокомерие, а не в гениальность?
Не решайте проблемы, которых у вас нет
Простой вопрос – какую проблему вы решаете? Это масштаб? Откуда вы знаете, как разбить так, чтобы это масштабировалось и имело хорошую производительность? Достаточно ли у вас данных, чтобы показать, какой сервис должен быть отдельным и почему? Распределенные системы созданы с учетом размера и устойчивости. Может ли ваша система масштабироваться и быть устойчивой одновременно? Что произойдет, если один из сервисов выйдет из строя или начнёт ползти? Просто увеличьте масштаб, да? А как насчет других сервисов, которые столкнутся с трафиком? Вы участвовали в бесконечных перестановках вещей, которые могут и могут пойти не так? Есть ли обратное давление? Автоматические выключатели? Очереди? Джиттер? Разумные тайм-ауты на каждой конечной точке? Существуют ли надежные средства защиты от простого изменения, которые не приведут к сбою всего? Ручки, о которых вам нужно знать и настраивать, бесконечны, и все они зависят от особенностей использования и трафика вашей системы.
Правда в том, что большинство компаний никогда не достигнут огромных размеров, которые фактически потребуют создания настоящей системы распределения. Ваша игра в Amazon и Google — без их масштаба, опыта и бесконечных ресурсов — скорее всего, просто вопиющая трата денег и времени.
Единственная вещь сложнее распределенной системы — это ПЛОХАЯ распределенная система.
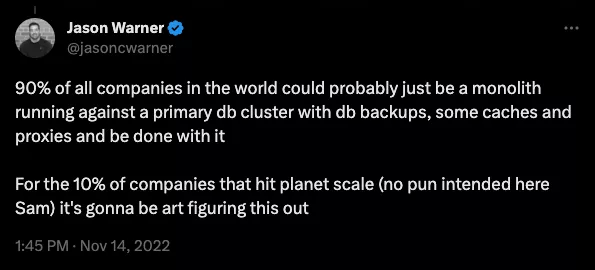
«Но каждая команда… но отдельная… но API»
Попытка внедрить распределенную топологию в структуру вашей компании — благородное усилие, но оно почти всегда приводит к обратным результатам. Распространенным подходом является разбиение проблемы на более мелкие части и последующее решение их одну за другой. Итак, если разбить один сервис на несколько, все станет проще, верно?
Теория приятна и элегантна: каждый микросервис строго поддерживается специальной командой, окруженной красивым API с обратной совместимостью и версионированием. На самом деле, все настолько жестко, что вам даже редко приходится общаться с этой командой — как если бы микросервис обслуживался сторонним поставщиком. Это просто!
Если это звучит вам незнакомо, то это потому, что такое случается редко. На самом деле наши каналы Slack переполнены сообщениями от команд, сообщающих о выпусках, ошибках, обновлениях конфигурации, критических изменениях и рекламных объявлениях. Каждый должен быть всегда на высоте. И если это не было здорово, то вполне нормально, когда одна и без того раскритикованная команда недооценивает несколько микросервисов вместо того, чтобы отлично работать над одним, часто меняя владельцев по мере того, как люди приходят и уходят.
Чтобы выиграть гонку, мы не строим одну хорошую гоночную машину — мы строим парк дерьмовых гольф-каров.
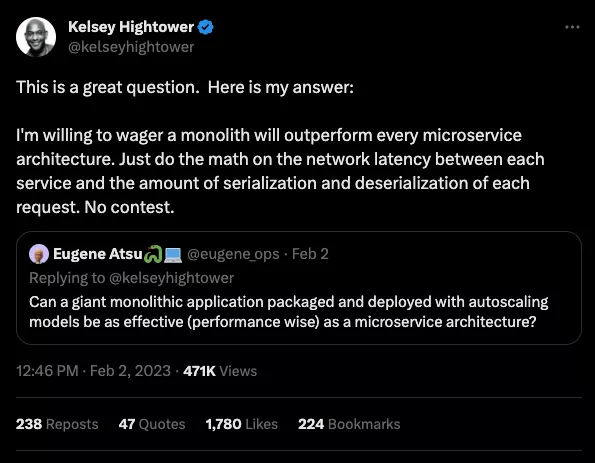
Что вы теряете
При создании микросервисов существует множество подводных камней, и часто это минное поле либо не осознается в полной мере, либо просто игнорируется. Команды тратят месяцы на написание узкоспециализированных инструментов и изучение уроков, совершенно не связанных с основным продуктом. Вот лишь некоторые аспекты, которые часто упускают из виду…
Попрощайтесь с DRY
После десятилетий обучения разработчиков написанию кода «Не повторяйся», кажется, мы вообще перестали об этом говорить. Микросервисы по умолчанию не являются DRY, поскольку каждый сервис наполнен избыточным шаблоном. Очень часто накладные расходы на то, что «под капотом» настолько велики, а размер микросервисов настолько мал, что средний экземпляр сервиса имеет больше «сервиса», чем «продукта». А как насчет общего кода, который можно вынести за рамки?
- Есть общая библиотека?
- Как обновляется общая библиотека? Хранить везде разные версии?
- Регулярно устанавливать обновления, создавая десятки запросов на включение во все репозитории?
- Хранить все это в монорепозитории? Это сопряжено со своими проблемами.
- Разрешить некоторое дублирование кода?
- Забудьте об этом, каждая команда каждый раз изобретает велосипед.
Каждая компания, идущая по этому пути, сталкивается с этим выбором, и хороших «эргономичных» вариантов не существует — приходится выбирать свой вариант боли.
Эргономика разработчиков ухудшится
«Эргономика разработчика» — это трение, количество усилий, которые должен приложить разработчик, чтобы что-то сделать, будь то работа над новой функцией или устранение ошибки.
При использовании микросервисов инженер должен иметь мысленную карту всей системы, чтобы знать, какие сервисы использовать для выполнения той или иной конкретной задачи, с какими командами общаться, с кем разговаривать и о чем. Принцип «надо все знать, прежде чем что-то делать». Как вам удается оставаться на высоте? Spotify, компания с оборотом в несколько миллиардов долларов, потратила, вероятно, немало внутренних ресурсов на создание Backstage, программного обеспечения для каталогизации своих бесконечных систем и сервисов.
Это должно, по крайней мере, дать вам понять, что эта игра не для всех, и цена поездки высока. Так что насчет инструментов? Те, кто не являются Spotify в мире, остаются создавать что-то со своими собственными решениями, о надежности и портативности которых вы, вероятно, можете догадаться.
А сколько команд реально упрощают процесс запуска YASS — «еще одного дурацкого сервиса»? Это включает в себя:
- Права разработчика в GitHub/GitLab
- Переменные среды и конфигурация по умолчанию
- CI/CD
- Проверка качества кода
- Код ревью
- Правила работы с ветками и защита
- Мониторинг и наблюдаемость
- Тестирование
- IoT
И, конечно же, умножьте этот список на количество языков программирования, используемых во всей компании. Может быть, у вас есть полезный шаблон или runbook? Может быть, систему, позволяющую запустить новый сервис с нуля в один клик? Чтобы устранить все недостатки такой автоматизации, требуются месяцы. Итак, вы можете либо работать над своим продуктом, либо работать над инструментарием.
Интеграционные тесты - LOL
Как будто повседневной работы с микросервисами недостаточно, вы также теряете душевное спокойствие, обеспечиваемое надежными интеграционными тестами. Ваши одиночные и модульные тесты проходят успешно, но остаются ли ваши критические пути нетронутыми после каждого коммита? Кто отвечает за общий набор интеграционных тестов, в Postman или где-то еще? Есть ли такой?
Интеграционное тестирование распределенной системы — практически неразрешимая задача, поэтому мы практически отказались от нее и заменили ее другой — Observability. Точно так же, как «микросервисы» — это новые «распределенные системы», «наблюдаемость» — это новая «отладка в производстве». Конечно, вы не напишете настоящее программное обеспечение, если не сделаете…. наблюдаемость!
Наблюдаемость стала отдельным сектором, и за него вы заплатите, как немалыми деньгами, так и временем разработчика. Это также не предполагает «подключи и плати» — вам нужно понимать и внедрять канареечные выпуски, флаги функций и т. д. Кто этим занимается? Один уже перегруженный инженер?
Как видите, дробление проблемы не облегчает ее решение: вы получаете другой набор еще более сложных проблем.
А как насчет просто «сервисов»?
Почему ваши сервисы должны быть «микро»? Что плохого в обычных сервисах? Некоторые стартапы дошли до того, что создали сервис для каждой функции, и да, «разве это не похоже на Lambda» будет справедливым вопросом. Это дает вам представление о том, как далеко зашел этот неконтролируемый карго-культ.
Так что же нам делать? Начать с монолита — один из очевидных вариантов. Во многих случаях также может работать шаблон «trunk and branches», где основному монолиту «meat and potatoes» помогают branch-сервисы. Branch-сервис может быть сервисом, который заботится о четко идентифицируемой и отдельно масштабируемой нагрузке. Сервис изменения размера изображений, требовательный к процессору, имеет гораздо больше смысла, чем сервис регистрации пользователей. Или у вас столько регистраций в секунду, что это требует независимого горизонтального масштабирования?

Примечание: во времена CVS и Subversion в системе контроля версий мы редко использовали «master» ветки. У нас был «trunk and branches», потому что, знаете ли, деревья. «Master» ветки появились где-то по пути, и когда GitHub решил покончить с довольно неудачным соглашением об именах, среднестатистический инженер был слишком молод, чтобы запомнить шаблон «trunk/branches», и поэтому появилось общее «main» значение по умолчанию.

Маятник качнулся назад
Однако ажиотаж, похоже, утихает. Денежный кран венчурного капитала ужесточается, и поэтому компании были скорректированы рынком и вынуждены принимать решения, основанные на здравом смысле, признавая, что, возможно, тратить деньги на архитектуру веб-масштаба, когда у них нет проблем веб-масштаба, не является устойчивым.

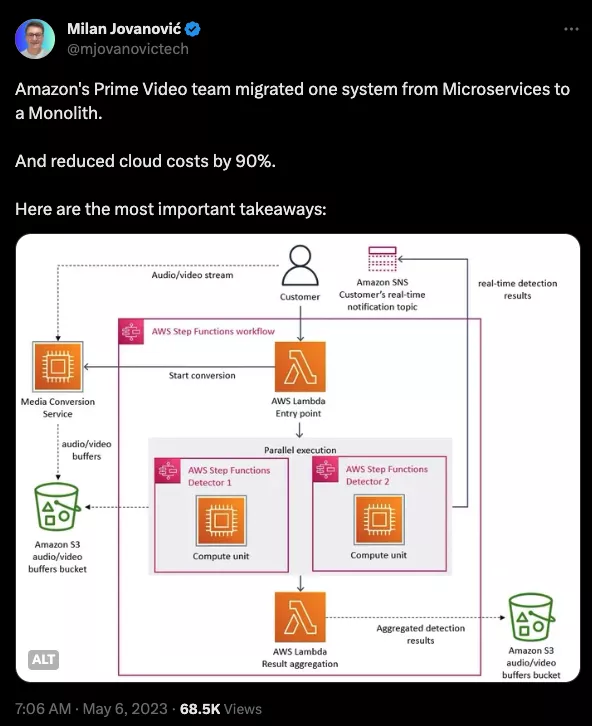
В конечном счете, когда вам необходимо поехать из Нью-Йорка в Филадельфию, у вас есть два варианта. Вы можете либо попытаться построить очень сложный космический корабль для спуска по орбите к месту назначения, либо просто купить билет на поезд Amtrak и совершить 90-минутную поездку. Вот и всё!